How to Detrmine Which Is the Best Product Base on Reviews
Predicting Product Quality using Customer Reviews
A deep dive into misleading customer ratings and how Bayesian thinking tricks our beliefs.
In a competitive market, the success of a company is built on satisfying the exacting standards of a consumer base with refined and discriminating gustation. In particular, customer product reviews are all important. Merely how should we judge the quality of a production based on client reviews?
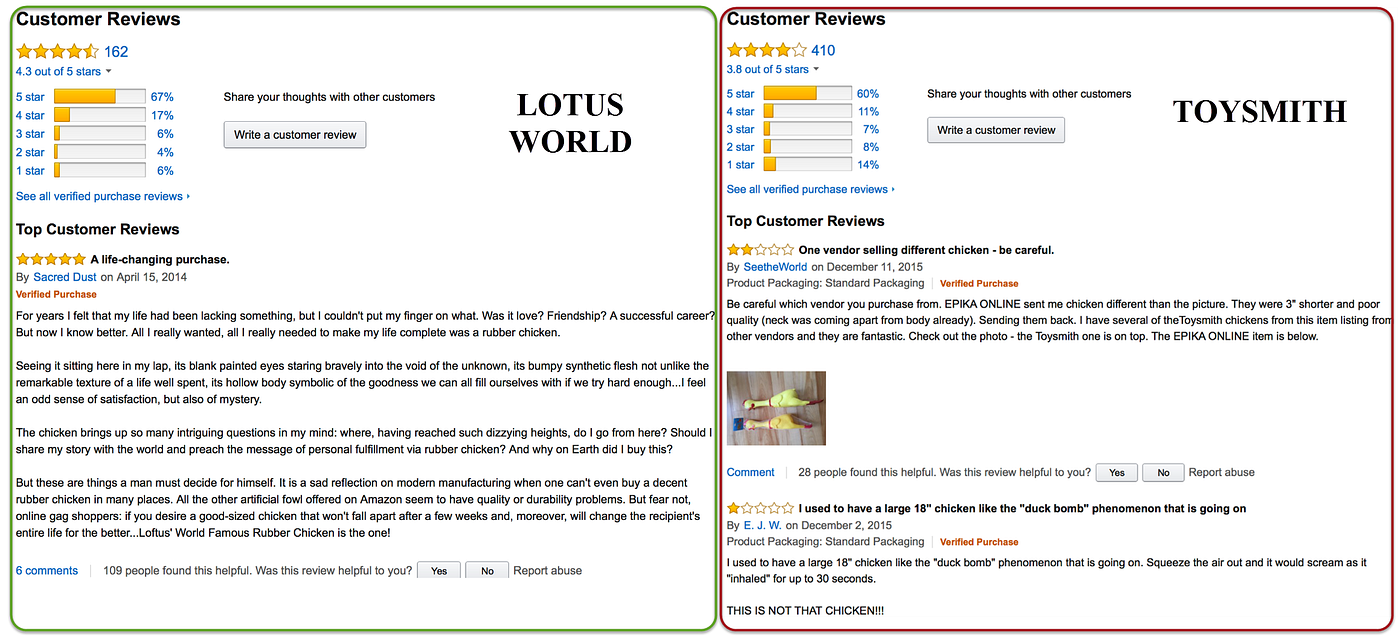
In this article, we build statistical models to compare ii virtual products (Lotus World versus Toysmith) using the observed rating from client reviews. In particular, we are looking at the number of times a product is rated a given rating (betwixt 1 and five stars).
Customer ratings are analyzed using Bayesian concepts such as maximum likelihood, maximum a posteriori, posterior mean estimate, posterior predictive estimate and credible interval.
If you need a refresher almost probabilities and distributions, the commodity below could be the right fit.
A Maximum Likelihood Model
We are interested in estimating θi the probability that customers rate with i number of stars. Since each new rating has a value betwixt 1 and 5, information technology follows a categorical distribution Cat(θ).
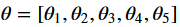
For a given product, we are given a vector of ratings R=[r1,rtwo,riii,rfour,r5]. Each rating r_i is the total number of i-star reviews. Each i-star review is fabricated with probability θi. We run into that each review r is independent of the others and is modeled by a categorical distribution:
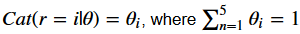
The likelihood of observing a vector of occurrences R out of North contained reviews is given by the multinomial distribution parametrized past θ :
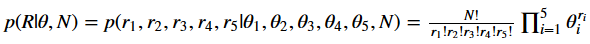
The log-likelihood volition be given by:
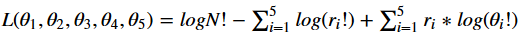
Now nosotros can calculate the Maximum Likelihood Estimator (MLE) of θ for each of both products. We need to discover the θ that maximizes the likelihood Fifty. We are going to need to differentiate the likelihood function with respect to θ. Notwithstanding, nosotros tin't only go alee and practise information technology. We have to have the constraint into accounts, nosotros accept to utilize the Lagrange multipliers.
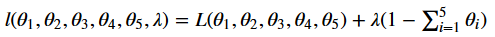
By posing all the derivatives to be 0, we become the nearly natural guess:
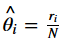
Therefore the maximum likelihood estimators are given below:
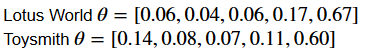
Based on this MLE of θ for both models, do you feel confident deciding if one production is superior to another? This is non straightforward. However, we tin can compute the Maximum Likelihood (ML) and the Akaike Data Criterion (AIC) to answer the question. The preferred model is the one with the minimum AIC value and maximum ML every bit shown below.
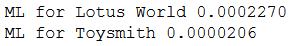

The Lotus Globe product seems to exist superior to Toysmith. How uncertain are nosotros about this?
A Bayesian Model
The maximum likelihood arroyo finds parameter values θ such that they maximize the likelihood that the review procedure described past the model produced the data that was really observed.
Prior Belief
As we explained in our previous article below, one drawback of MLE is the impossibility to include our prior belief most those parameters nosotros are estimating.
Suppose we are told that customer opinions are very polarized in the market.
Near reviews will be v stars or 1 star, with very few of them in the centre ground. A Dirichlet prior on θ would profoundly capture this fact. The Dirichlet distribution is sampling over a probability simplex, a bunch of numbers that add up to 1.
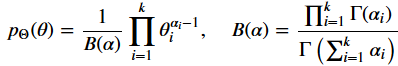
Dirichlet models the probabilities of multiple, mutually exclusive choices, parameterized by α which is referred to as the concentration parameter and represents the weights for each choice.
If nosotros would like to produce consistently fair reviews, then α→∞. For a symmetric Dirichlet distribution with α>1, we will produce a off-white review, on average. If the goal is to produce biased reviews, with a higher probability of 1 and 5 stars, nosotros would want an asymmetric Dirichlet distribution with a higher value for α1 and α5. Below we suggest an instance of asymmetric alphas.
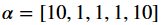
Posterior Distribution
The Bayesian approach tin be seen every bit an extension of maximum likelihood interpretation. When nosotros accept information, priors, and a generative model, we can apply Bayes theorem to compute the posterior probability distribution of the model parameters conditionally upon the data as follows.
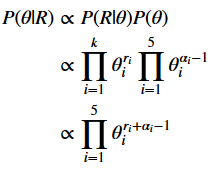
Maximum a posteriori (MAP)
It is mutual to summarize the posterior distribution to find some central trend. The Maximum A Posteriori (MAP) or posterior mode is the indicate with the highest posterior probability, given by:
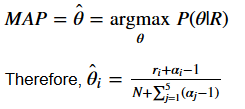
Below we implement the formula to compute MAP for Lotus World versus Toysmith. This gives the states an idea of a more realistic probability of ratings we could expect in the future. For example, the likelihood for a customer to provide a 5-star rating to Lotus Earth is rather 65%, later considering the prior belief of disproportionate reviews. The MLE model provided a chip more than optimistic value for that probability (67%). By including prior conventionalities from domain experts, the Bayesian approach only allows estimates which are more close to the business reality.

If we ready α to i, and so nosotros obtain the maximum likelihood gauge for θi.


Posterior Hateful Estimate (PME)
The Posterior Mean Estimate or expected value is the mean or way of the posterior distribution. For our problem, it is given by the formula below.
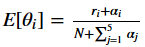

Bayesian Inference with PyMC3
So far we have computed the posterior distribution analytically by hand. Although it is conceptually elementary, this approach can be incredibly slow and calibration horribly with a large dataset.
In that location are faster methods, mostly inside the so-called Markoff chain Monte Carlo (MCMC) family of algorithms. Beneath nosotros implement MCMC to detect the posterior distribution of the model parameters using the Python library PyMC3. This allows us to sample 1000s rating vectors from the posterior predictive for each production and to summarize the Posterior Predictive Estimates for theta.
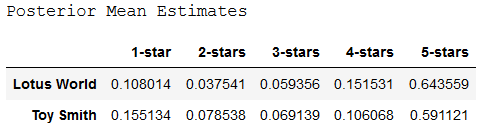
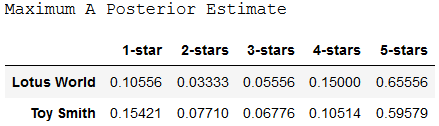
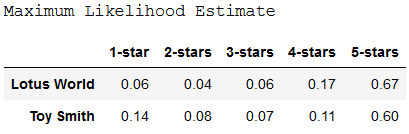
While Posterior Mean Estimates and Maximum A Posterior Estimates are very similar, both are quite unlike from Maximum Likelihood Estimates.
Apparent Interval
The credible interval tells u.s.a. the possible range of values of an unobserved parameter value with a detail probability. This is not to be dislocated with the confidence interval, which does non capture our current doubt in the location of the parameter values.
Below we use the posterior distribution (samples from it) to compute the 95% credible interval of θ for each product.
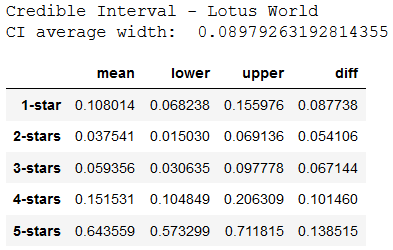
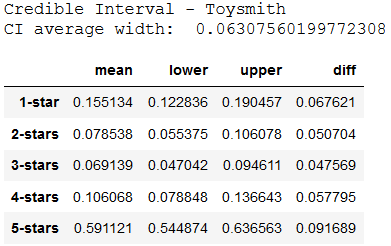
The credible intervals for posterior hateful estimates above are on boilerplate narrower for Toysmith. We might tend to add together more trust to the reviews fabricated on the Toysmith product.
Which signal estimate (MAP, MLE, posterior mean PME, or posterior predictive estimate) of θ would you cull to rank the ii products?
The average rating does non take prior belief into consideration, such equally skewed ratings towards 1 and 5 stars. As we demonstrated above the probability that a customer would requite a specific review is more credible when including priors.
In our example, nosotros would choose for the posterior mean guess (PME). MLE and MAP are similar, as they compute a single estimate, instead of a full distribution. MLE is a special instance of MAP, where the prior is uniform! PME or posterior predictive approximate is drawn from the posterior predictive distribution, which is the distribution of possible parameters. Therefore PME will provide a more credible prediction that will become even more authentic with increasing information volume.
Decision
We have applied the Bayesian approach to detect the perceived quality of ii products based on client ratings. Python code was provided for a applied demonstration.
Feel free to learn more nigh the Bayesian approach in my side by side article below.
I further recommend the following resources:
- Bayesian Inference by prof. Larry Wasserman,
- Bayesian Inference for Dirichlet-Multinomials past prof. Marking Johnson,
- Dice, Polls & Dirichlet Multinomials past Claus Herther.
Thanks for reading. Stay safe!
Source: https://towardsdatascience.com/predicting-product-quality-using-customer-reviews-ac1a215226d1
0 Response to "How to Detrmine Which Is the Best Product Base on Reviews"
Post a Comment